hi,大家好,我是赵壮实,很高兴和大家又一次相聚在「一个数据人的自留地」中。整个11月-12月的周六,我会跟你分享关于大数据底层的内容。
经常会有同学问我们,数据产品经理对于技术要理解到什么程度,壮实觉得这玩意,就是“有下限没有上限”的事情。而《壮实学数据技术》就是满足各位数据人的技术下限。
毕竟,数据产品经理还有需要有一些货,和技术小哥保持认知一致。

好啦,话不多说,我们进入今天的《壮实学数据技术 01——初识数据仓库》
01 数据工具、数据内容之外,我们还需要什么?
假设你是一个埋点产品的pm,你需要考虑实时数据和离线数据不同的上传方式;
假设你是一个大盘数据sql查询的pm,你需要考虑用户使用不同引擎的查询速度;
假设你一个数据仓库模型产品的pm,你需要了解数仓分类、主题分型、表分类等等概念。
实际上,如果我们能理解如下这些母题,就能基本上达到了数据技术的入门,可以和数据RD小哥哥你来我往较量一番。
实时/离线;计算/存储;线上/线下;引擎;数仓主题;表内涵/分类/外延;指标/维度;数据接入-产生-生产-调度监控;
02初识数据仓库
数据仓库,顾名思义,就是数据的“储藏间”。数据来源于外部,并且开放给外部应用。因此,数据仓库的基本架构主要包含的是数据流入流出的过程,它本身不生产也不消费任何数据,只做数据的接受、加工和存储。80年代,学术界渐渐开始将数据仓库提升到理论的高度进行定义。Bill Inmon关于数据仓库的定义较为广泛,他认为,数据仓库是一个面向主题、集成的、相对稳定、反映历史变化的数据集合,并用于支持管理决策。
我们来依次拆解下Bill Inmon关于数据仓库的定义:
1
面向主题
主题,我们可以理解为业务下不同的分支。举个栗子,互联网公司消费金融业务,可以分为金融、保险、贷款等等主题。
2
集成的
我们把数据入库—清洗—整合成统一的标准化数据的过程就叫做“集成”。举个栗子,保险业务可能有汽车保险、养老保险、意外保险,但是它们的单位有的是元(RMB),有的是美元($),有的是千元(K),这就需要进行数据“集成”,把他们的单位进行统一,才能加减乘除。
3
相对稳定的
数据仓库中的数据相对稳定,进入数据仓库之后就会被长期保留,较少地进行修改与删除,一般是定期的加载与更新。
4
时变性
数据仓库中会保存各个日期节点的数据,以满足不断变化的业务的需求。
所以,综上所述,数据仓库是一个用于存放数据的“工厂”,在这个工厂中,有主题“货架”,货架上的数据还经过去杂质和标准化;这个工厂会每天进货“数据”,且比较稳定。
03 数据仓库的“宗教战争”
我们说完数据仓库的概念, 说说数据仓库的内涵。除了上述提到的Inmon,还有一个不得不提就是Kimball,为了方便,我们就称他们为ai萌和金大伯伯。ai萌是数据仓库之父,主张自上而下的设计数据仓库;金大伯伯是斯坦福大学电子工程博士,主张自下而上的数据集市设计方案和维度建模方法论。他们两者对于数据仓库体系结构的最佳问题,始终存在分歧,甚至有人把他们两个的分歧称之为数据仓库界的“宗教战争”。

1
ai萌:范式建模
我们刚才在前面开宗明义的数据仓库定义就是这位ai萌制定的,他所建立的数据仓库整体还是面向表的、面向记录的,面向结构化数据。
范式模型都是以数据源头为导向。
首先,获取尽可能符合预期的数据,将数据按照预期划分为不同的表需求。
其次,明确数据的清洗规则后将各个任务通过ETL由Stage层转化到DW层,这里DW层通常涉及到较多的UDF开发,将数据抽象为实体-关系模型。
接着,在完成DW的数据治理之后,可以将数据输出到数据集市中做基本的数据组合。
最后,将数据集市中的数据输出到BI系统中去辅助具体业务。
但是,今天ai萌的范式建模今天面临了多重危机。具体来说,有以下2点弱势:
1.对非结构化数据的处理缺乏足够的高效的处理能力
2.适用于业务模式较为稳定的传统的公司
2
金大伯伯:维度建模
金大伯伯的模式从流程上看是是自底向上的,即从数据集市-数据仓库-数据源(先有数据集市再有数据仓库)的一种敏捷开发方法。
首先,在得到数据后需要先做数据的探索,尝试将数据按照目标先拆分出不同的表需求。
其次,在明确数据依赖后将各个任务再通过ETL由Stage层转化到DM层。这里DM层数据则由若干个事实表和维度表组成。
接着,在完成DM层的事实表维度表拆分后,数据集市一方面可以直接向BI环节输出数据了,另一方面可以先DW层输出数据,方便后续的多维分析。
金大伯伯的模式不会对数据仓库架构做过多复杂的设计,在变换莫测的互联网行业,这种架构方式逐渐成为一种主流。
总之,数据仓库的建模或者分层,其实都是为了更好的去组织、管理、维护数据,实际开发时会整合这两种方式去使用,当然,还有些其他的,像Data Vault模型、Anchor模型,壮实暂且不表。
04 数据如何通过数据仓库到你的面前?
数据仓库的基本架构主要包含的是数据流入流出的过程,可以分为三层——源数据、数据仓库、数据应用。
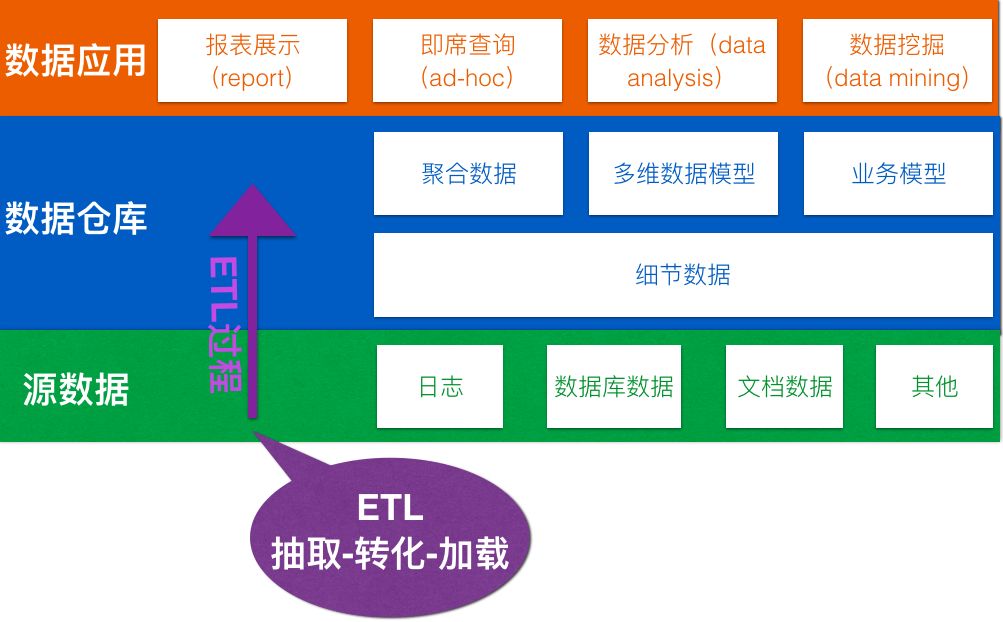
1
源数据
源数据,顾名思义,就是来源数据。数据来源可以来源流日志、数据库数据、Excle表等数据文件、爬虫数据等等。如PC端,流日志是一块主要的数据来源,它是网站分析的基础数据;数据库数据也并不可少,这些数据可以记录网站运营数据及各种用户操作结果。
数据仓库
数据仓库是一个中间集成化的数据管理平台。各数据源的数据进入数据仓库后,便会经过ETL。ETL就是按照数据仓库的规则和要求,对各个源系统的数据进行加工和整合,并且将各个源系统的数据存储到数据仓库中。ETL 是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持 ETL 的正常和稳定。
3
数据应用
其实一切基于数据相关的扩展性应用都可以基于数据仓库来实现,所以壮实列出了以下4种数据应用场景。
1.报表展示
报表几乎是每个数据仓库的必不可少的一类数据应用,将聚合数据和多维分析数据展示到报表,提供了最为简单和直观的数据。
2.即席查询
即席查询(细节数据、聚合数据、多维数据和分析数据)提供了足够灵活的数据获取方式,用户可以根据自己的需要查询获取数据,并提供导出到 Excel 等外部文件。
3.数据分析
数据分析大部分可以基于构建的业务模型,也可以使用聚合的数据进行趋势分析、比较分析、相关分析等,还可以通过多维数据模型提供了多维分析的数据基础;同时,从细节数据中获取一些样本数据进行特定的分析也是较为常见的一种途径。
4.数据挖掘
大多数时候数据挖掘会直接从细节数据上入手,而数据仓库为挖掘工具诸如 SAS、SPSS 等提供数据接口。
好啦,相信你对数仓概念、数仓模型、数据在数仓中的流转已经有了基本的认知。是不是





发表评论 取消回复