关注微信公众号:一个数据人的自留地 作者介绍 @猫耳朵 数据产品经理萌新, 开发经验丰富,专注于数据产品。 越来越多的小伙伴想要入行或者转行数据分析,作为圈内老鸟,将使用 pandas 和 Matplotlib 分析一下数据分析师岗位目前现状,希望可以帮到他们。 01 分析目标 1) 公司都要求掌握什么技能? 2) 学历要求高吗? 3) 薪资怎么分布? 4) 不同细分领域对数据分析的需求情况? 5) 各大城市对数据分析岗位的需求情况? 6) 工作经验与薪水有什么关系? 7) 不同规模的企业对经验的要求以及提供薪资的水平是什么? 02 数据加载 部分数据如下图所示 03 数据预处理 1)过滤非数据分析的岗位 2)用均值作为相应职位的薪水 薪水是一个区间,所以用薪水区间的均值作为相应职位的薪水 3)提取技能要求 将技能分为:Python、SQL、Tableau、Excel、SPSS/SAS、R、数据挖掘。如果job_detail中含有这些技能,则赋值为1,否则为0 04 数据可视化分析 1)各城市对数据分析师的需求量 如下图得知,一线城市数据分析师岗位较多,其中北京数据分析师岗位需求最多,其次是上海需求紧随其后。 2)不同行业对数据分析师的需求量 如下图得知,电商对于数据分析师的需求量最大,其次是金融。 3)各城市薪资状况 如下图得知,北京薪资最高,其次上海仅次于杭州。 4)工作经验与薪水关系 如下图所示,数据分析师的工作经验与薪水成正比,北京工作10年以上的年薪是应届毕业生的5倍。 5)学历要求 如下图所示,85.36%的数据分析师岗位的学历要求最低是本科,5.22%的岗位要求最低是硕士。 6)技能要求 如下图所示,Python/R的异常值、中位数最高,SQL的上限较高,并且上限和下限差别最大。 7)大公司对技能要求 由下图得知,大公司要求最多的是数据挖掘,其次是SQL、Python。 8)不同规模的公司在招人要求上的差异 由下图得知,大部分公司对工作经验为3年以上的求职者,需求量大。其中,需求量最大的是中大型公司。 05 结论 1)北京为数据分析师需求量最大的一线城市; 2)一线城市的数据分析师岗位的薪资很有竞争力; 3)数据分析工程师的核心技能:数据挖掘、SQL、Python等。import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontManager
from matplotlib import gridspecjobData = pd.read_csv('zhaopin.csv')jobData.drop_duplicates(inplace = True) # 删除重复数据jobData
isTrue = jobData['positionName'].str.contains('数据分析')# 职位中是否包含‘数据分析’
jobData = jobData[isTrue] # 筛选出想要的字段
jobData.reset_index(inplace=True) # 重置行索引
jobDatajobData['salary'] = jobData['salary'].str.lower()\
.str.extract(r'(\d+)[k]-(\d+)k')\
.applymap(lambda x:int(x))\
.mean(axis=1) # 用薪水区间的均值作为薪水jobDatajobData['job_detail'] = jobData['job_detail'].str.lower().fillna('') # 将字母小写,缺失值赋为空字符串
jobData['python'] = jobData['job_detail'].map(lambda x:1 if('python' in x) else 0)
jobData['SQL'] = jobData['job_detail'].map(lambda x:1 if('sql' in x) or ('hive' in x) else 0)
jobData['Tableau'] = jobData['job_detail'].map(lambda x:1 if 'tableau' in x else 0)
jobData['Excel'] = jobData['job_detail'].map(lambda x:1 if 'excel' in x else 0)
jobData['SPSS/SAS'] = jobData['job_detail'].map(lambda x:1 if ('spss' in x) or ('sas' in x) else 0)
jobData['R'] = jobData['job_detail'].map(lambda x:1 if('r' in x) else 0)
jobData['数据挖掘'] = jobData['job_detail'].map(lambda x:1 if('挖掘') else 0)
jobDataplt.rcParams['font.family'] = 'Heiti TC'
plt.figure(figsize=(12, 9))
cities = jobData['city'].value_counts()
plt.barh(y = cities.index[::-1],
width = cities.values[::-1],
color = '#78a355')
plt.box(False) # 不显示边框
plt.title(label='各城市数据分析岗位的需求量',
fontsize = 32, weight = 'bold', color = 'white',
backgroundcolor = '#f47920', pad = 30)
plt.tick_params(labelsize = 16)
plt.grid(ls = '--', axis = 'x', linewidth = 0.5, color = '#78a355')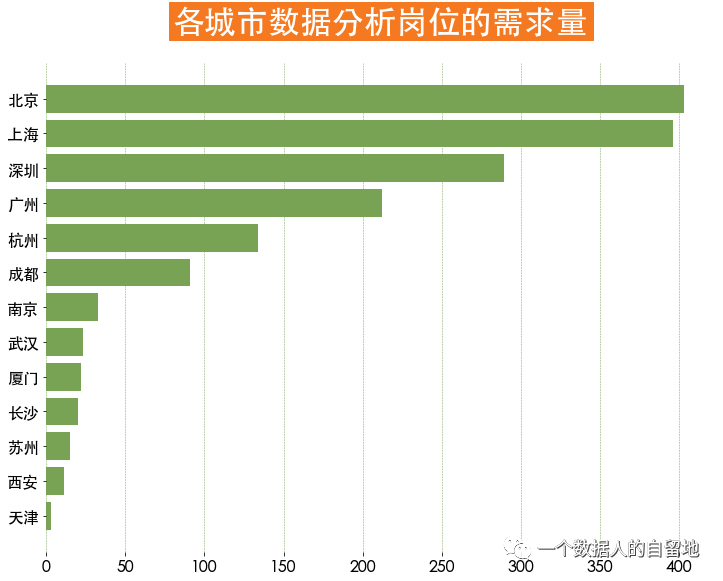
industry_index = jobData['industryField'].value_counts()[:10].index
industry = jobData.loc[jobData['industryField'].isin(industry_index), 'industryField']
plt.figure(figsize=(12, 9))
plt.barh(y = industry_index[::-1],
width=pd.Series.value_counts(industry.values).values[::-1],
color = '#78a355')
plt.box(False) # 不显示边框
plt.title('不同领域对数据分析岗位的需求量(前十)',
fontsize = 32, weight = 'bold', color = 'white',
backgroundcolor = '#f47920', pad = 30)
plt.tick_params(labelsize = 16)
plt.grid(ls = '--', axis = 'x', linewidth = 0.5, color = '#78a355')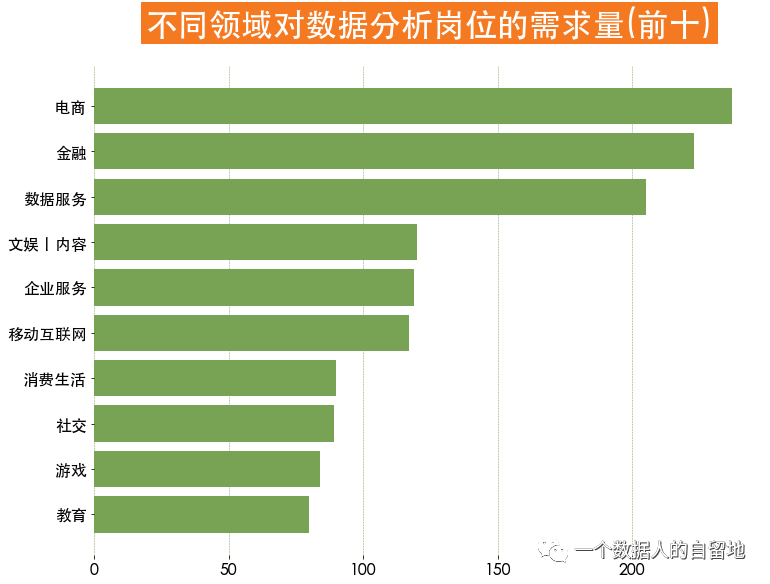
plt.figure(figsize=(12, 9))
city_salary = jobData.groupby('city')['salary'].mean().sort_values(ascending=False)
plt.bar(x = city_salary.index, height = city_salary.values,
color = plt.cm.coolwarm_r(np.linspace(0,1,len(city_salary))))
plt.title('各大城市的薪资对比',
fontsize = 32, weight = 'bold', color = 'white',
backgroundcolor = '#f47920', pad = 30)
plt.tick_params(labelsize = 16)
plt.grid(ls = '--', axis = 'y', linewidth = 0.5, color = '#a1a3a6')
plt.yticks(ticks=np.arange(0, 25, step=5), labels=['', '5k', '10,', '15k', '20k'])
plt.box(False)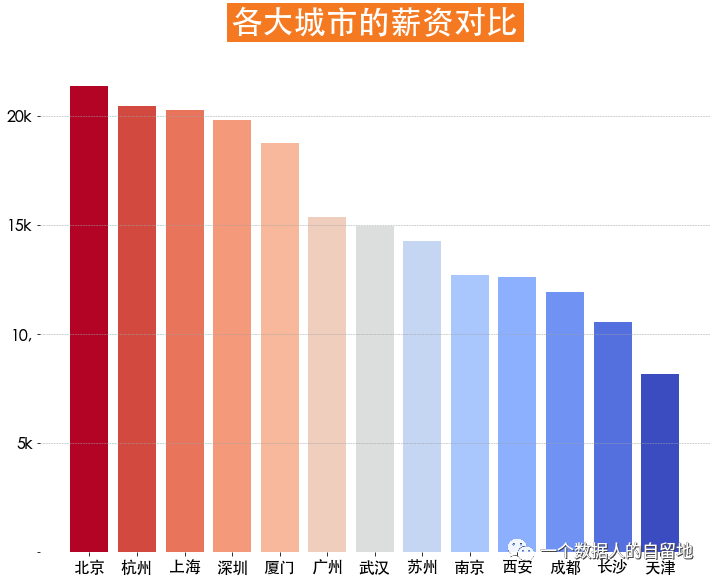
work_salary = jobData.pivot_table(index='city', columns='workYear', values='salary')
work_salary = work_salary[['应届毕业生', '1-3年', '3-5年', '5-10年', '10年以上']]\
.sort_values(by='10年以上', ascending=False)
data = work_salary.values
data = np.repeat(data, 4, axis=1)
plt.figure(figsize=(12, 9))
# plt.cm.OrRd_r
plt.imshow(data, cmap='RdBu_r')
plt.yticks(np.arange(13), work_salary.index)
plt.xticks(np.array([1.5, 5.5, 9.5, 13.5, 17.5]), work_salary.columns)
h, w = data.shape
for x in range(w):
for y in range(h):
if (x%4==0) and (~np.isnan(data[y, x])):
text = plt.text(x+1.5, y, round(data[y, x], 1),
ha='center', va='center', color='r', fontsize=16)
plt.colorbar(shrink=0.72)
plt.title('工作经验与薪水关系',
fontsize = 32, weight = 'bold', color = 'white',
backgroundcolor = '#f47920', pad = 30)
plt.tick_params(labelsize = 16)
education = jobData['education'].value_counts(normalize=True)
plt.figure(figsize=(9, 9))
plt.pie(education, labels=education.index, autopct='%0.2f%%',
wedgeprops=dict(linewidth=3, width=0.5), pctdistance=0.8,
textprops=dict(fontsize=20))
plt.title(label='学历要求',
fontsize=32, weight='bold',
color='white', backgroundcolor='#f47920')def get_level(x): if x['python'] == 1: x['skill'] = 'Python/R' elif x['R'] == 1: x['skill'] = 'Python/R' elif x['SQL'] == 1: x['skill'] = 'SQL' elif x['Excel'] == 1: x['skill'] = 'Excel' elif x['SPSS/SAS'] == 1: x['skill'] = 'SPSS/SAS' else: x['skill'] = '其他' return xjobData = jobData.apply(get_level, axis=1) # 数据转换# 获取主要技能x = jobData.loc[jobData.skill!='其他'][['salary', 'skill']]condition1 = x['skill'] == 'Python/R'condition2 = x['skill'] == 'SQL'condition3 = x['skill'] == 'Excel'condition4 = x['skill'] == 'SPSS/SAS'plt.figure(figsize=(12, 8))plt.title(label='不同技能的薪资水平对比', fontsize=32, weight='bold', color='white', backgroundcolor='#f47920', pad=30)plt.boxplot(x=[jobData.loc[jobData.skill!='其他']['salary'][condition1], jobData.loc[jobData.skill!='其他']['salary'][condition2], jobData.loc[jobData.skill!='其他']['salary'][condition3], jobData.loc[jobData.skill!='其他']['salary'][condition4]], vert=False, labels=['Python/R', 'SQL', 'Excel', 'SPSS/SAS'])plt.tick_params(axis='both', labelsize=16)plt.grid(axis='x', linewidth=0.75)plt.xticks(np.arange(0, 61, 10), [str(i)+'k' for i in range(0, 61, 10)])plt.box(False)plt.xlabel('工资', fontsize=18)plt.ylabel('技能', fontsize=18)
job_skills = jobData[jobData['companySize'] == '2000人以上']labels = ['Python', 'SQL', 'Tableau', 'Excel', 'SPSS/SAS', '数据挖掘']counts =[]counts.append(jobData['python'].sum())counts.append(jobData['SQL'].sum())counts.append(jobData['Tableau'].sum())counts.append(jobData['Excel'].sum())counts.append(jobData['SPSS/SAS'].sum())counts.append(jobData['数据挖掘'].sum())plt.figure(figsize=(9, 6))plt.bar(x=labels, height=counts, width=0.5, color=plt.cm.coolwarm_r(np.linspace(0,1,len(counts))))np.linspace(0,1,len(counts))plt.title(label='大公司对技能的要求', fontsize=32, weight='bold', color='white', backgroundcolor='#f47920', pad=30)plt.tick_params(labelsize=16,)plt.grid(axis='y')plt.box(False)
color_map = { 5:"#ff0000", 4:"#ffa500", 3:"#c5b783", 2:"#3c7f99", 1:"#0000cd"}cond = jobData.workYear.isin({'5-10年':5, '3-5年':4, '1-3年':3, '1年以下':2, '应届毕业⽣':1})jobData = jobData[cond]jobData['workYear'] = jobData.workYear.map(workYear_map)# 根据companySize进⾏排序,⼈数从多到少jobData['companySize'] = jobData['companySize'].astype('category')# list_custom = ['2000⼈以上', '500-2000⼈','150-500⼈','50-150⼈','15-50⼈','少于15⼈']list_custom = ['2000人以上', '500-2000人', '150-500人', '50-150人', '15-50人', '少于15人']# inplace = True,使 recorder_categories生效jobData['companySize'].cat.reorder_categories(list_custom, inplace=True)# inplace = True,使 df生效jobData.sort_values(by = 'companySize',inplace = True,ascending = False)plt.figure(figsize=(12,11))gs = gridspec.GridSpec(10,1)plt.subplot(gs[:8])plt.suptitle(t=' 不同规模公司的⽤⼈需求差异 ', fontsize=32, weight='bold', color='white', backgroundcolor='#3c7f99')# 画散点图plt.scatter(jobData.salary,jobData.companySize, c = jobData.workYear.map(color_map), s = (jobData.workYear*100), alpha = 0.35)plt.scatter(jobData.salary,jobData.companySize, c = jobData.workYear.map(color_map))plt.grid(axis = 'x')plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])plt.xlabel('⼯资', fontsize=18)plt.box(False)plt.tick_params(labelsize = 18)# 绘制底部标记plt.subplot(gs[9:])x = np.arange(5)[::-1]y = np.zeros(len(x))s = x*100plt.scatter(x,y,s=s,c=color_map.values(),alpha=0.3)plt.scatter(x,y,c=color_map.values())plt.box(False)plt.xticks(ticks=x,labels=list(workYear_map.keys()),fontsize=14)plt.yticks(np.arange(1),labels=[' 经验:'],fontsize=18)


投稿

微信公众账号
微信扫一扫加关注
评论 返回
顶部
发表评论 取消回复