作者介绍 @猫耳朵 数据产品经理萌新。 开发经验丰富,专注于数据产品。 —————— BEGIN —————— 本文主要围绕架构、分层、建模三个方面,进一步加深对数仓的了解。1 数据仓库的架构
从整体上来看,数据仓库体系架构可分为:数据采集层、数据计算层、数据服务层和数据应用层,如下图。
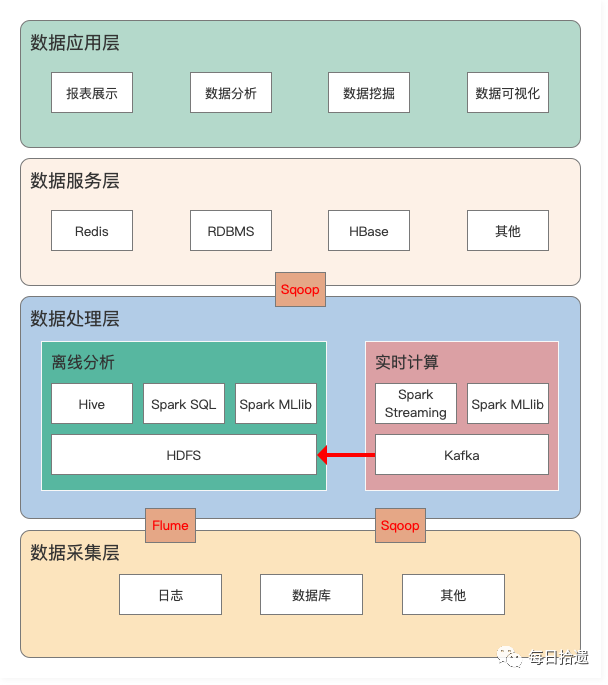
1)数据采集层
数据采集层的任务就是把数据从各种数据源中采集和存储到数据库上,期间有可能会做一些 ETL(即抽取、转换、装载)操作。
其中,日志所占份额最大,存储在备份服务器上的业务数据库中,如 Mysql 中的数据。其他数据的话,如 Excel 等需要手工录入的数据。
实时采集不是一条一条采集,而是根据一些限制条件,一般是数据大小限制(如 512KB 写一批)、时间阈值限制(如 30 秒写一批)。
采集的数据需要数据采集系统分发给下游,一般选取 Flume、Sqoop 等。
2)数据处理层
从数据采集系统出来的数据,分发给下游的数据处理平台,一般有 Hive、MapReduce、Spark Streaming、Storm 以及新兴的 Flink 等,阿里巴巴内部使用的是 StreamCompute。
3)数据服务层
数据服务层,通过接口服务化方式对外提供数据服务,以保证更好的性能和体验。针对不同的需求和数据应用场景,数据服务层的数据源架构在不同的数据库上,如 Mysql、HBase、MongoDB 等。实时的存储且需要支持高并发的话,就选择 HBase。
数据服务层可以使应用对底层数据存储透明,将海量数据方便高效地开放给各业务使用。
4)数据应用层
数据已经准备好,需要通过合适的应用提供给用户,让数据最大化地发挥价值。数据应用表现在各个方面,如报表展示、数据分析、数据挖掘、数据可视化等。
2 数据仓库分层
2.1 为啥要分层?
作为一名数据产品经理,笔者肯定希望自己的数据能够有秩序地流转,数据的整个生命周期能够清晰明确地被设计者和使用者感知到。但是,随着业务的发展,频繁迭代和跨部门的业务变得越来越多。这就容易导致数据仓库出现如下问题:
1)缺乏统一的业务和技术标准,如:开发规范、指标口径不统一。
2)缺乏统一数据质量监控,如:字段数据不完整和不准确等。
3)业务知识体系散乱,导致数据研发人员开发成本增加。
4)数据架构不合理,数据层之间分工不明显,数据流向混乱。
5)缺失统一维度和指标管理。
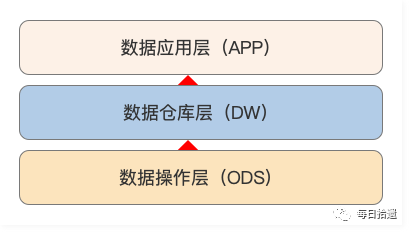
因此,笔者需要一套行之有效的方法来让自己的数据仓库更有秩序,这就需要对数据进行分层,如下图。

2.2 数据分层设计
按照数据操作的流程,笔者将数据模型分为三层:数据操作层(ODS)、数据仓库层(DW)和数据应用层(APP),如下图。简单来讲,ODS 层存放的是接入的原始数据,DW 层存放的是数据仓库中的数据,APP 层存放的是面向业务定制的应用数据。
1)数据操作层(ODS)
数据操作层又叫数据运营层,英文:Opertional Data Source。数据操作层是最接近数据源中数据的一层,数据源中的数据,经过 ETL(即抽取、转换、装载),装入本层。本层中的数据,大多是按照源业务系统的分类方式而分类的。
由于该层是最接近数据源的,所以不建议对该层数据做过多的数据清洗工作,原封不动地接入原始数据就行,至于数据的去噪、去重、去异常值等操作可以放在后面的 DWD 层来做。
2)数据仓库层(DW)
数据仓库层,英文:Data Warehouse,是笔者在设计数据仓库时要核心设计的一层。在这里,从 ODS 层获得的数据按照主题建立各种的数据模型。DW 层又要细分为 DWD(Data Warehouse Detail)层、DWM(Data Warehouse Middle)层和 DWS(Data Warehouse Service)层,如下图。
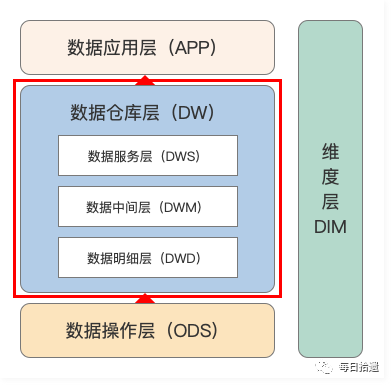
(1)数据明细层(DWD)
数据明细层,英文:Data Warehouse Detail,该层和 ODS 层一般保持一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化的方法,将维度退化至事实表,减少事实表和维表的关联。
另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性。
(2)数据中间层(DWM)
数据中间层,英文:Data Warehouse Middle,该层会在 DWD 层的数据基础上,对数据做轻度的聚合,生成一系列的中间表,提升公共指标的复用性,减少重复加工。直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
(3)数据服务层(DWS)
数据服务层又叫数据集市或宽表,英文:Data Warehouse Service。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询、OLAP 分析、数据分发等。
一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称为该层的表为宽表。
在实际计算中,如果直接从 DWD 或者 ODS 计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在 DWM 层先计算出多个小的中间表,然后再拼接成一张 DWS 的宽表。由于宽和窄的界限不易界定,也可以去掉 DWM 这一层,只留 DWS 层,将所有的数据放在 DWS 亦可。
3)数据应用层(APP)
数据应用层,英文:Application,该层主要提供给数据产品和数据分析使用的数据。该层的数据一般会存放在 Redis、PostgreSql 等共线上系统使用的系统,也可能会存放在 Hive、Druid 中供数据分析和数据挖掘使用,比如报表数据就可以存放在 Hive 中。
4)维度层(DIM)
维度层,英文:Dimension。建立一致数据分析维表,可以降低数据计算口径和算法不统一风险。以维度作为建模驱动,基于每个维度的业务含义,通过定义维度及维度主键,添加维度属性、关联维度等定义计算逻辑和雪花模型,完成属性定义的过程并建立一致的数据分析维表。同时笔者可以定义维度主子关系,子维度的属性将合并至主维度使用,进一步保证维度的一致性和便捷使用性。
维度层包含两个部分:
(1)高基数维度数据:一般是用户资料表、商品资料表类似的资料表,数据量可以上千万甚至上亿。
(2)低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维度表,数据量大概在几千到几万之间。
3 数据仓库建模
3.1 数仓建模目标
大数据的数据仓库建模需要通过建模的方法更好地组织、存储数据,以便在性能、成本、效率和数据质量之间找到最佳平衡点。具体的建模目标,如下图。

3.2 数仓建模方法
接下来,就聊聊数据仓库中几种经典的数据模型,如关系建模、维度建模、DataVault模型。在实际工作中,通常会根据业务场景选择一种或几种模型。
3.2.1 关系建模
关系建模,是数据仓库之父 Inmon 推崇的,被称为 “实体-关系” 模型,以一种 “标准化” 的方式存在,强调数据之间非冗余,满足 3NF 。关系建模是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系抽象。它更多用于数据的整合和一致性质量。
3.2.2 维度建模
维度建模,Ralph Kimball 博士最先提出这一概念。其最简单的描述就是,按照事实表、维表来构建数据仓库、数据集市。这种方法很多人称之为星形模型。之所以称为星形模型是因为它的表示方法是以一颗 “星” 为中心,周围围绕着其他数据结构,如下图。
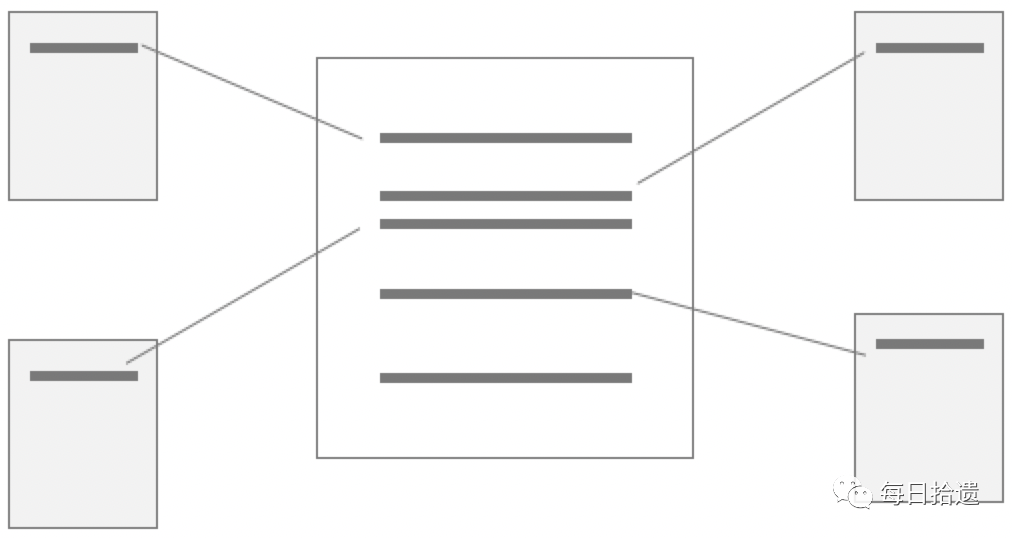
星形模型的中心是一张事实表。事实表是包含大量数据值的一种结构。事实表的周围是维表,用来描述事实表的某个重要方面。维表里的数据量要比事实表里的少。
星形模型之所以广泛被使用,在于针对各个维作了大量的预处理,比如按照维进行了预先的排序、分类、统计等。通过这些预处理,能够极大地提升数据仓库的处理能力。特别是针对 3NF 的建模方法,星形模型在性能上占据明显的优势。因此,星形模型仅适用于小范围数据(如一个部门或甚至一个子部门)。
通常星形模型只包含一张事实表。但是在数据库设计中要创建一种雪花结构的复合结构,需要多张事实表结合。如下图,描绘了一个雪花模型。
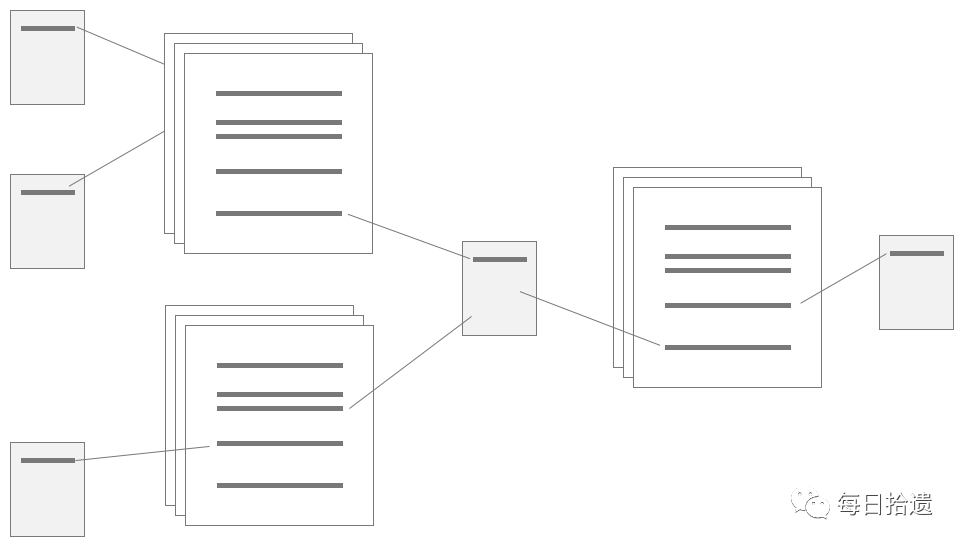
在雪花模型中,不同的事实表通过共享一个或多个公共维表连接起来。有时称这些共享的维表为一致维表。
维度建模的最大优点在于访问的高效性。如果设计适当,通过星形连接将数据传递给最终用户是非常高效的。为了提高传递信息的效率,必须收集并吸收最终用户的请求。最终用户使用数据的过程是要定义什么样的多维结构的核心。一旦清楚了最终用户的请求,这些请求就可以用来最终确定星形模型,形成最理想的结构。
因此笔者认为,维度建模主要适用于数据集市层,它的最大作用其实是为了解决数据仓库建模中的性能问题。维度建模很难提供一个完整地描述真实业务实体之间的复杂关系的抽象方法。
3.3 Data Vault 模型
Data Vault 是另一种数据仓库建模方法,是 Dan Linstedt 在 20 世纪 90 年代提出的,主要用于企业级的数据仓库建模。
Data Vault 需要跟踪所有数据的来源,因此其中每个数据行都要包含数据来源和装载时间属性,用以审计和跟踪数据值对应的源系统。
Data Vault 不区分数据在业务层面的正确与错误,它保留操作型系统的所有时间的所有数据,装载数据时不做数据验证、清洗等工作,这点明显有别于其他数据仓库建模方法。
Data Vault是对 ER 模型更近一步的规范化,由于对数据的拆解更偏向于基础数据组织,在处理分析类场景时相对复杂,适合数据仓库底层构建,目前实际应用场景较少。
1)Data Vault模型定义
Dan Linstedt 将 Data Vault 模型定义为:Data Vault 是面向细节的,可追踪历史的,一组由连接关系的规范化的表的集合。这些表可以支持一个或多个业务功能。它是一种综合了第三范式和星型模型特点的建模方法。
Data Vault 只按照业务数据的原样保存数据,不做任何解释、过滤、清洗、转换。即使从不同数据源来的数据是自相矛盾的,比如:同一个客户有不同的地址,Data Vault 模型会存储多个不同版本的地址数据。
2)Data Vault 模型的特点
(1)所有数据都基于时间来存储,即使数据是低质量的,也不能在 ETL 过程中处理掉。
(2)与源系统越独立越好。
(3)可以适应源系统中数据的各种变化,并可以灵活的实现模型扩展。
(4)数据的来源可以完全追踪,并且数据处理作业可以支持重载。
(5)ETL 作业可以重复执行。
3)Data Vault 模型组成
Data Vault 模型由中心表(Hub)、链接表(Link)、附属表(Satellite)三个主要组成部分。其中,中心表是核心,用于存储业务主键,链接表记录业务关系,附属表记录业务描述。
(1)中心表
中心表用来存储企业每个业务实体的业务主键,业务主键唯一标识某个业务实体。中心表和源系统是相互独立的,即无论业务主键是否用于多个业务系统,它在 Data Vault 中只保留一份,其他的组件都链接到这一个业务主键上。
出于设计上的考虑,中心表一般由主键、业务主键、装载时间戳、数据来源系统四个字段组成。其中主键是系统生成的代理键,仅供内部使用。
(2)链接表
链接表是不同中心表的链接。一个链接表一般在两个或多个中心表之间有关联。一个链接表通常是一个外键,表示一种业务关系,比如:交易表、客户关联账户等。
链接表主要包括主键、外键1、……、外键n、装载时间戳、数据来源系统等字段构成,其中主键对应多个外键的唯一组合,一般是与业务无关的序列数值。
(3)附属表
附属表用来保存中心表和链接表的描述属性,包含所有历史变化数据,附属表有且仅有一个唯一外键关联到中心表或链接表。
附属表主要包括主键、外键、属性1、……、属性n、装载时间、失效时间、数据来源系统,主键用于唯一标识附属表中的一行记录,一般是与业务无关的序列数值。
4)Data Vault 模型设计
根据 Data Vault 模型体系构成,Data Vault 模型设计由此也分成三大部分。
(1)设计中心表
明确企业数据仓库要涵盖的业务范围。
按业务范围划分为若干原子业务实体,比如客户、产品、品类等。
从各个业务实体中抽象出业务主键,该业务主键要在整个业务的生命周期内不会发生变化。
由该业务主键生成中心表。
(2)设计链接表
分析各个中心表代表的业务实体之间的业务关系,并识别对应的中心表,这些业务关系可以是1对1、1对多,或者多对多的。
按业务关系涉及的中心表,提取中心表主键,这些主键将被加入到链接表中,并确定链接表的主键。
在生成链接表的同时,链接表内可以保存交易数据,有两种方法,一是采用加权链接表,二是给链接表加上附属表来处理交易数据。
(3)设计附属表
附属表包含了各个业务实体与业务关联的详细的上下文描述信息。主要是从中心表、链接表出发,提取与中心表、链接表相关的上下文描述信息。
由于同一业务实体的各个描述信息不具有稳定性,会经常发生变化,因此需要按变化频率不同的信息分割开来,为一个中心表建立几个附属表,然后提取主键,作为描述该中心表的附属表的主键。
(4)设计必要的 PIT 表
为了访问数据的方便,可能就用到 PIT 表,PIT 表不是必须的,但如果一个中心表或者链接表有多个附属表,就有可能用到 PIT 表。PIT 表的主键是由附属表关联的中心表提取出来的,有几个附属表就会有几个字段用于记录附属表的变化时间戳。




学习中